

Performance review calibration meetings are broken in most organizations. Not because managers don't care, but because the way these meetings are structured practically guarantees inconsistent outcomes.
Last month I watched this play out at a 400-person tech company. Their calibration meeting for engineering reviews ran six hours. Thirty-two managers arguing over ratings for 187 engineers. No structured agenda, no scoring anchors — just opinions bouncing around a conference room while someone frantically updated a spreadsheet.
By hour four, managers were rubber-stamping ratings just to get out of there. Junior engineers from Team A got "exceeds expectations" for shipping features on time. Team B's engineers got "meets expectations" for pushing a critical security update ahead of schedule. Same performance level, different ratings, mostly based on who spoke loudest.
Three months later, an engineer filed a discrimination complaint. HR couldn't defend the ratings because there was no documentation of the calibration logic. Just that messy spreadsheet and some half-remembered conversations.
The $47,000 mistake hiding in plain sight
Most HR teams think calibration meetings fix bias. Without proper operational structure, they actually amplify it.
A retail chain with 22 stores found this out after getting sued. Store managers met quarterly to calibrate ratings for around 340 employees. No framework, no rubric — managers would pull up files on their laptops and debate based on memory and gut feel.
The pattern was predictable. Managers from high-revenue stores dominated the room. Their employees consistently landed higher ratings, which meant bigger bonuses and faster promotions. Employees doing identical work at smaller stores got rated lower, even when their individual metrics were stronger.
When the lawsuit came, the company needed to prove their ratings were fair and consistent. They couldn't. No standardized examples, no rating rubrics, no documentation of why specific decisions were made. The settlement ran $47,000 plus legal fees, and they had to overhaul their entire performance management process.
What makes this frustrating is that fixing it isn't complicated. You need three operational components: pre-meeting data packs, calibration anchors, and decision documentation. Most companies have none of these.
Why managers can't agree on what "meets expectations" means
The core problem with calibration isn't bias or politics — it's that different managers genuinely define performance levels differently.
Eliminate HR bottlenecks with smart automation.
Hiryly simplifies your HR operations so you can focus on people, not paperwork.
- Centralized candidate tracking
- Automated onboarding workflows
- Performance & compliance dashboards
No credit card required
Manager A thinks "meets expectations" means completing assigned tasks on time. Manager B thinks it means completing tasks and helping teammates. Manager C factors in attitude and initiative. Without standardized definitions, they're not even having the same conversation.
This gets messier when departments enter the mix. Sales managers rate on revenue. Engineering managers rate on code quality. Customer service rates on ticket resolution. Try calibrating across all three without clear cross-functional anchors and it falls apart fast.
Then there's the recency problem. Managers remember last month clearly but forget strong performance from eight months ago. The employee who just wrapped a visible project gets rated higher than the one who delivered consistently all year but had a quiet December.
Regional culture makes it worse. Some offices just rate harder than others — same performance, different rating, based purely on geography. Without structured calibration, those differences quietly get baked into compensation and promotion decisions.
The pre-meeting data pack that stops arguments before they start
Companies that run effective calibrations prep data packs five to seven days before the meeting. Not just performance metrics — structured evidence packages that shift conversations from opinion-based to evidence-based.
Here's what belongs in the data pack:
Employee Performance Snapshot
-
Current rating from direct manager with specific examples
-
Last two review ratings for trend context
-
Key deliverables from the review period (not just recent ones)
-
Peer feedback summary if available
-
Any documented performance conversations
Comparative Context
-
Distribution curve showing where this rating falls
-
Similar roles/levels and their proposed ratings
-
Department-wide rating distribution
-
Historical rating patterns for this employee
Decision Points
-
Specific rating recommendation
-
If borderline, which way manager leans and why
-
Impact on compensation/bonus
-
Promotion readiness indicator
When managers walk in with this data, discussions focus on comparing evidence rather than debating opinions.
The marketing manager can't claim their coordinator deserves "exceeds" without showing deliverables that actually exceed the standard. The engineering manager can't lowball ratings without explaining why shipped features don't warrant higher scores.
Scoring anchors that make "meets expectations" mean the same thing everywhere
Generic rating scales are useless. "Meets expectations" needs to mean something specific, observable, and consistent across every team.
Behavioral anchors tied to actual work examples are the most effective approach:
| Rating Level | Individual Contributor Example | Manager Example | Cross-Functional Evidence |
|---|---|---|---|
| Exceeds | Delivered project 2 weeks early + mentored 2 junior employees + identified process improvement saving 10hrs/month | Team hit 110% of goals + reduced turnover by 30% + led successful cross-department initiative | Documented impact beyond core role + measurable improvement in team metrics + recognized by other departments |
| Meets | Completed all assigned projects on timeline + participated in team meetings + maintained quality standards | Team achieved 95-100% of goals + maintained team stability + executed department priorities | Fulfilled role requirements + collaborated as needed + no quality issues |
| Below | Missed 2+ deadlines or quality issues requiring rework + needed excessive supervision | Team missed goals by >10% or had 2+ escalated issues + required intervention from leadership | Incomplete deliverables + collaboration challenges + required performance conversation |
Notice these aren't vague descriptions. They include specific thresholds — 2+ missed deadlines, 110% of goals, 30% reduction in turnover. That eliminates the "but I think they exceeded expectations" arguments when the evidence clearly shows standard performance.
You also need different anchors for different levels. An entry-level analyst "exceeding" looks different than a senior analyst exceeding. Build these before reviews start, not during calibration.
The facilitator script that keeps meetings from becoming popularity contests
Most calibration meetings fall apart because nobody's actually running them. There's a difference between scheduling a meeting and facilitating calibration.
The facilitator needs to control pace, cut off tangents, and make sure every rating gets proper scrutiny. Here's the structure that holds up in practice:
Opening (5 minutes) "We're reviewing [X] employees today across [Y] teams. Everyone should have the data packs. We'll spend a maximum of 5 minutes per employee unless flagged for extended discussion. Ratings need to align with our anchors — I'll push back on any rating that doesn't match the evidence presented."
Per Employee Review (5 minutes max)
-
Manager presents
rating, 2-3 specific examples, comparison to anchors (90 seconds)
-
Clarifying questions only (60 seconds)
-
Anyone disagrees? If yes, flag for parking lot. If no, confirm rating (30 seconds)
-
Document decision and rationale (120 seconds)
Parking Lot Discussion (after initial pass)
-
Return to flagged employees
-
Manager presents additional evidence
-
Dissenting voice explains their concern
-
Group compares to anchors and similar ratings already given
-
Decision by consensus or escalation rule
Closing Validation
-
Review final distribution curve
-
Confirm it matches organizational expectations
-
Flag anomalies for VP review
-
Document all changes made during calibration
The script matters because it keeps the loudest voice from running the room. Everyone gets the same time. Evidence requirements are consistent. Decisions get documented in real time.
Here's a quick visual of the facilitator workflow.
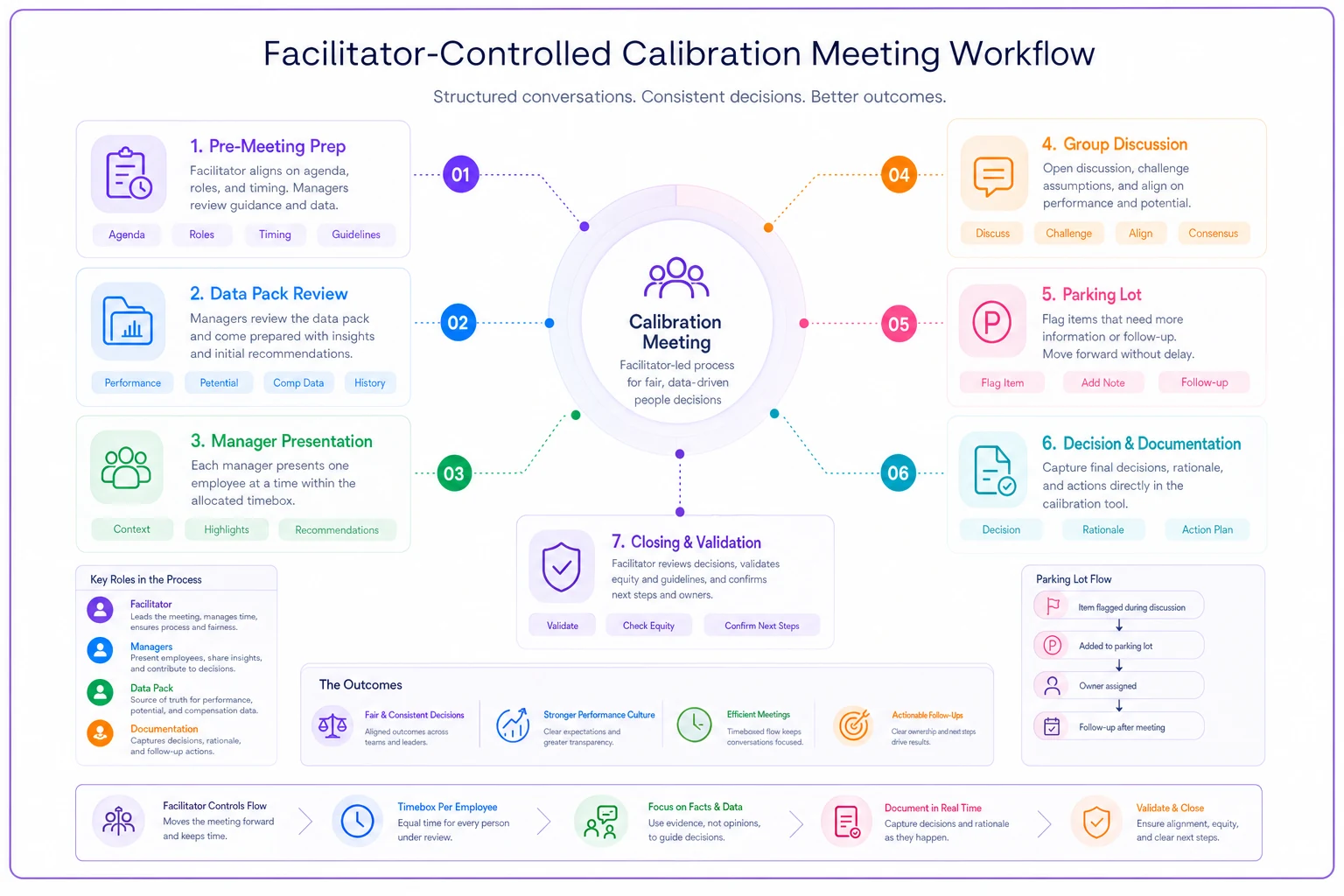
Use the visual to align facilitators on timing and required evidence during each step.
Post-calibration templates that survive legal scrutiny
This is where most companies completely drop the ball. They update ratings in their HRIS and move on. Six months later when someone challenges a decision, there's nothing explaining how it was made.
Three templates you need after every calibration:
Individual Rating Justification
-
Employee name and role
-
Final rating given
-
3-4 specific performance examples supporting this rating
-
Comparison to role expectations and anchors
-
Calibration adjustments made (if any) and why
-
Manager signature and date
Calibration Session Summary
-
Date, attendees, facilitator
-
Number of employees reviewed
-
Initial vs. final rating distribution
-
Key themes or patterns discussed
-
Specific calibration rules applied
-
Decisions requiring escalation
Department Calibration Report
-
Overall rating distribution with commentary
-
Year-over-year rating trends
-
Consistency analysis across teams
-
Identified process gaps
-
Recommendations for next cycle
These aren't administrative busywork. When a discrimination claim arrives, these documents prove you had a consistent, defensible process. They show ratings were based on performance evidence, not manager preference.
The 90-day implementation reality check
You can't fix calibration overnight, especially in organizations with years of entrenched habits. Here's a realistic rollout:
Days 1–30: Foundation
-
Build anchors for three to five key roles first. Don't try to cover everyone immediately. Get specific with behavioral examples and test them with a small group of managers to find the gaps.
-
Build your data pack template. Keep it to two pages per employee maximum or managers won't complete them. Automate pulling quantitative metrics where possible.
Keep it to two pages per employee maximum or managers won't complete them.
Days 31–60: Pilot
-
Run a pilot calibration with one department — somewhere around 20-30 employees is the right size. Use the facilitator script strictly. Document every deviation and why it happened.
-
After the pilot, gather feedback. Managers will complain about the time investment. That's expected. Show them the alternative is inconsistent ratings and legal exposure.
Days 61–90: Rollout
-
Train all managers on the new process. Mandatory, not optional. Include HR business partners who'll be facilitating.
-
Run your first full calibration with the new process. Expect it to take longer than old meetings initially. The second cycle moves faster once everyone understands what's expected.
Run your first full calibration with the new process. Expect it to take longer than old meetings initially. The second cycle moves faster once everyone understands what's expected.
When software automation prevents the predictable disasters
The manual process breaks at scale. Calibrating 500+ employees with spreadsheets and shared documents creates operational chaos — data gets lost, versions conflict, and decisions don't get tracked properly.
AI-powered operational software changes this in a meaningful way. Instead of managers arguing ratings from memory, the platform tracks performance data continuously throughout the year. Project completions, peer feedback, one-on-one notes — all of it gets aggregated and surfaced during calibration.
The software can present comparative analytics automatically. It shows you that one employee's "exceeds" puts them in the 95th percentile for their level, while another employee's "meets" in a different department actually reflects stronger relative performance. Rating inconsistencies get flagged before they become problems.
Documentation happens in the background too. Every rating decision, every calibration adjustment, every manager comment gets logged with timestamps. When HR needs to defend a rating months later, the full decision trail is already there.
And some platforms can surface bias patterns that humans miss in the moment. If engineers in one demographic consistently rate lower than peers with similar performance metrics, the system flags it before calibration is finalized. If certain managers habitually rate above or below peers, that gets surfaced for discussion rather than quietly baking into outcomes.
The truth about fair performance reviews
Fairness in performance reviews isn't about making everyone happy. It's about having a consistent, defensible process that evaluates people on actual performance — not manager preference or departmental politics.
Most organizations say they want fair reviews but won't invest in the operational infrastructure to make it real. They run unstructured calibrations, make undocumented decisions, and seem genuinely surprised when employees feel the process is arbitrary.
The tools in this guide — data packs, anchors, scripts, templates — aren't revolutionary. They're basic operational discipline applied to a process that directly affects people's careers and compensation. Companies that implement them see the results fairly quickly: fewer rating appeals, better legal defensibility, and employees who actually trust the process.
The upfront investment is roughly 20 hours of initial setup and 2-3 hours of preparation per calibration cycle. Compare that to the cost of a single discrimination lawsuit, or the productivity loss from employees who've stopped believing the system is fair.
Performance calibration doesn't have to be a political fight. With the right structure, it becomes what it was always supposed to be — a fair assessment of contributions that guides development and rewards performance. The companies getting sued aren't victims of difficult employees. They're organizations that skipped building proper processes and are now dealing with the consequences.
Fairness in performance reviews isn't about making everyone happy. It's about having a consistent, defensible process that evaluates people on actual performance — not manager preference or departmental politics.
Most organizations say they want fair reviews but won't invest in the operational infrastructure to make it real. They run unstructured calibrations, make undocumented decisions, and seem genuinely surprised when employees feel the process is arbitrary.
The tools in this guide — data packs, anchors, scripts, templates — aren't revolutionary. They're basic operational discipline applied to a process that directly affects people's careers and compensation. Companies that implement them see the results fairly quickly: fewer rating appeals, better legal defensibility, and employees who actually trust the process.
The upfront investment is roughly 20 hours of initial setup and 2-3 hours of preparation per calibration cycle. Compare that to the cost of a single discrimination lawsuit, or the productivity loss from employees who've stopped believing the system is fair.
Performance calibration doesn't have to be a political fight. With the right structure, it becomes what it was always supposed to be — a fair assessment of contributions that guides development and rewards performance. The companies getting sued aren't victims of difficult employees. They're organizations that skipped building proper processes and are now dealing with the consequences.
Ready to transform your HR processes?
Join thousands of HR teams using Hiryly to hire faster, engage employees better, and stay compliant effortlessly.